

Hui Ding, PhD
I work on vision-language sequence modeling and text-to-image generation with diffusion models.
Work Experience
![]()
![]()
![]()
![]()
![]()
Publications
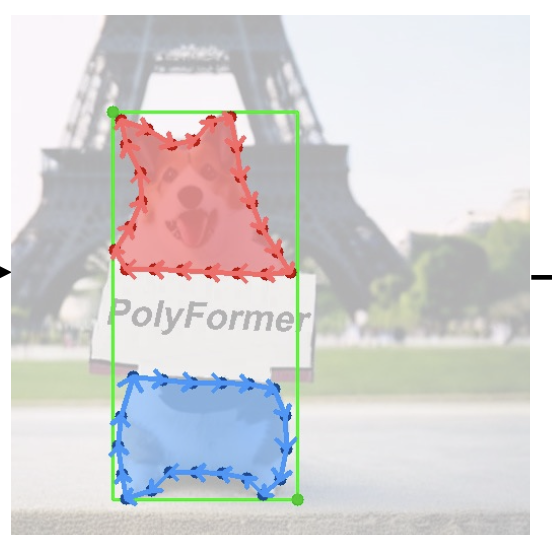
PolyFormer: Referring Image Segmentation as Sequential Polygon Generation

Learning Self-Consistency for Deepfake Detection
[paper]
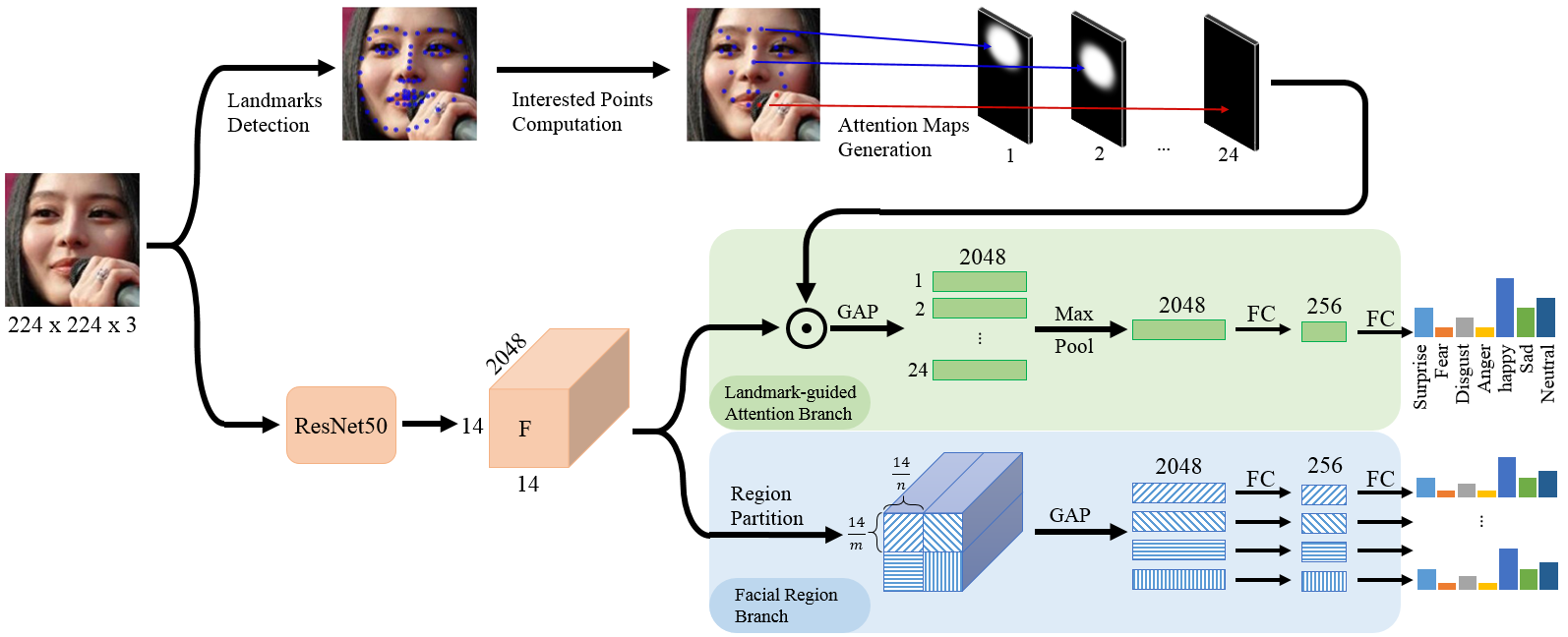
Occlusion-Adaptive Deep Network for Robust Facial Expression Recognition
[paper]

ExprGAN: Facial Expression Editing with Controllable Expression Intensity
Hui Ding, Kumar Sricharan and Rama Chellappa
Association for the Advancement of Artificial Intelligence (AAAI), 2018. (Oral)
[paper][code][model][slides]
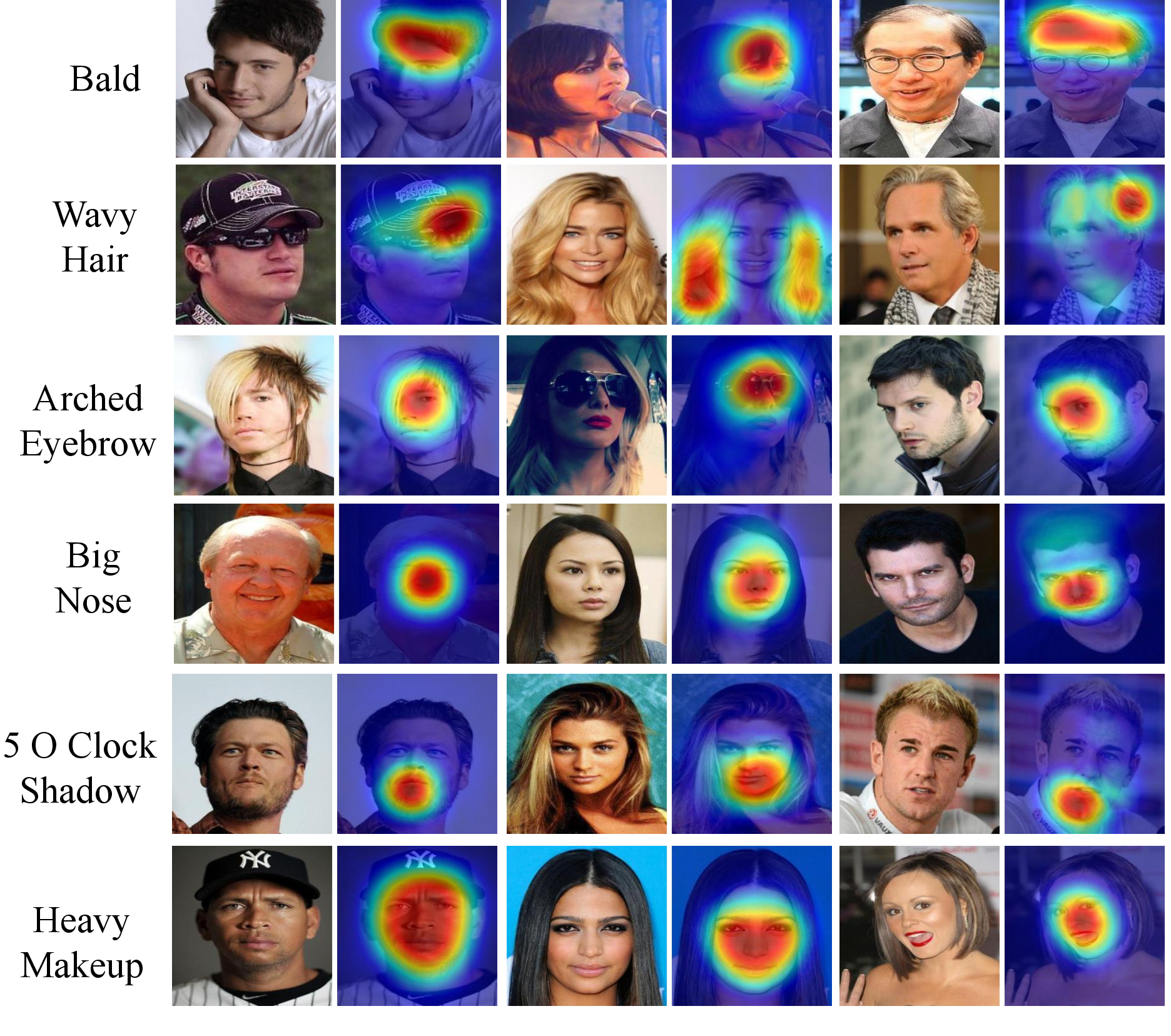
A Deep Cascade Network for Unaligned Face Attribute Classification
Hui Ding, Hao Zhou, Shaohua Kevin Zhou and Rama Chellappa
Association for the Advancement of Artificial Intelligence (AAAI), 2018. (Spotlight)
[paper]

Hui Ding, Shaohua Kevin Zhou and Rama Chellappa,
IEEE International Conference on Automatic Face Gesture Recognition (FG), 2017.
[paper][model][poster]
Hui Ding, Chen He, and Lingge Jiang, “Performance Analysis of Fixed Gain MIMO Relay Systems in the Presence of Co-Channel Interference”, IEEE Commun. Lett., vol. 16, no. 7, pp. 1133-1136, Jul. 2012.
Hui Ding, Chen He, and Lingge Jiang, “Performance of Multi-antenna Systems with Fixed Gain AF Relay in the Presence of Co-Channel Interference”, 2012 IEEE International Conference on Communications (ICC), pp. 5538-6642.
Ph.D. Thesis
Service
- Journal Reviewer: TPAMI, IJCV, TIP, TMM
- Conference Reviewer: CVPR, ICCV, ECCV